
숫자 데이터 요약하기
COUNT 함수
- 집계 함수 정리
1. COUNT : 행의 수를 나타냄
=> NULL값을 포함한 전체 행의 수 : COUNT(*)
=> NULL값을 제외한 전체 행의 수 : COUNT(열 이름)
=> 중복을 제외한 행의 수 : COUNT(DISTINCT 열 이름)
2. SUM : 행의 합계를 나타냄
3. AVG : 행의 평균을 나타냄
4. MAX : 행의 최댓값을 나타냄
5. MIN : 행의 최솟값을 나타냄
6. STDENV : 행의 표준편차를 나타냄
7. VARIANCE : 행의 분산을 나타냄
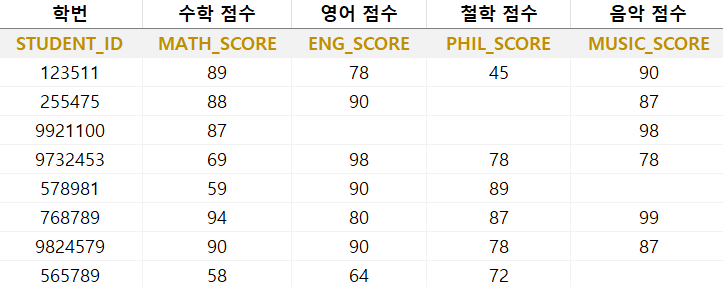
1. STUD_SCORE 테이블을 사용하여 NULL 값을 제외한 음악 점수 보유자를 세려면?
SELECT COUNT(MUSIC_SCORE) AS MUSIC_CNT
FROM STUD_SCORE;
2. STUD_SCORE 테이블을 사용하여 NULL값 및 중복된 값을 제외한 영어 점수 보유자를 세려면?
SELECT COUNT(DISTINCT ENG_SCORE) AS ENG_CNT
FROM STUD_SCORE;
COUNT 함수는 데이터의 검증용으로도 많이 사용됨
=> 특정한 테이블을 만들었을 때 그 테이블에 NULL값이나 중복된 값이 있는지 눈으로 찾기 힘듬
(COUNT로 쉽게 검증 가능)
3. STUD_SCORE 테이블을 사용하여 음악 점수의 평균을 구하려면?
AVG 함수를 사용하면 NULL값을 가진 열은 계산에서 생략되어 전체 평균값이 잘못될 수 있으므로 주의해야함!!
=> COALESCE 사용
SELECT AVG(COALESCE(MUSIC_SCORE, 0)) AS MUSIC_AVG
FROM STUD_SCORE;
4. STUD_SCORE 테이블을 사용하여 수학 점수의 최댓값 및 최솟값을 구하려면?
SELECT MAX(MATH_SCORE) AS MAX_SCORE, MIN(MATH_SCORE) AS MIN_SCORE
FROM STUD_SCORE;
1. 집계 함수를 사용하면 NULL값은 계산에서 무시된다
2. 별칭을 지정할 때 테이블에 존재하는 열 이름이 아닌 새로운 이름으로 지정하는 것이 좋음
3. 숫자형 데이터를 분석할 때 SUM, AVG,MIN,MAX 값을 사용하여 데이터를 검증하는 것은 중요함
조건문 이해하기
CASE WHEN 문장
1. CASE WHEN 문장
[조건1]을 만족하면 [결과값1]을 나타내고, [조건2]를 만족하면 [결과값2]를 나타낸다
나머지는 [결과값3]으로 보여주고 이들 결과값은 [새로운 열 이름]으로 나타내라는 뜻이다!
=> 조건물을 나태낼 때 사용되고 활용도가 높음
SELECT 열 이름1,
CASE WHEN [조건1] THEN [결과값1]
WHEN [조건2] THEN [결과값2]
ELSE [결과값3] END AS 새로운 열 이름
FROM 테이블명;
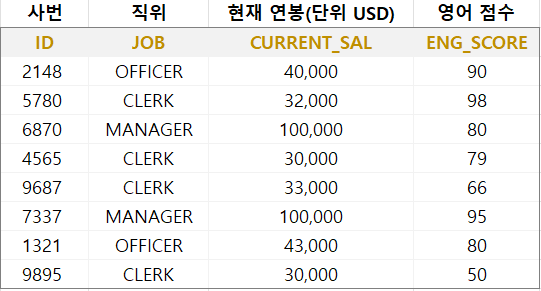
1. CLERK는 7%, OFFICER는 5%, MANAGER는 3%로 연봉을 인상하기로 했을 때 STAFF_SAL 테이블을 사용하여 각 직원별 인상 연봉을 예상하려면?
SELECT ID, JOB, CURRENT_SAL,
CASE WHEN JOB = 'CLERK' THEN CURRENT_SAL * 1.07
WHEN JOB = 'OFFICER' THEN CURRENT_SAL * 1.05
WHEN JOB = 'MANAGER' THEN CURRENT_SAL * 1.03
ELSE CURRENT_SAL END AS NEXT_SAL
FROM STAFF_SAL;
CASE WHEN 함수에서 EQUAL 조건만 있을 경우 DECODE 함수를 사용할 수 있다
(DBMS 특성에 따라 지원이 안되는 경우도 있음)
DECODE 함수 문법 :
DECODE(열 이름, 조건1, 결과값1,
조건2, 결과값2,
조건3, 결과값3, 기본값) 새로운 열 이름)
'🫧 Database > SQL' 카테고리의 다른 글
| 테이블 합치기 (1) | 2024.02.29 |
|---|---|
| 데이터의 그룹화, 필터링 (1) | 2024.02.27 |
| SQL 기본 함수 배우기 (2) | 2024.02.26 |
| 텍스트 마이닝을 활용한 데이터 조건 주기 (1) | 2024.02.26 |
| 논리연산자를 활용한 데이터 조건 주기 (0) | 2024.02.25 |
숫자 데이터 요약하기
COUNT 함수
- 집계 함수 정리
1. COUNT : 행의 수를 나타냄
=> NULL값을 포함한 전체 행의 수 : COUNT(*)
=> NULL값을 제외한 전체 행의 수 : COUNT(열 이름)
=> 중복을 제외한 행의 수 : COUNT(DISTINCT 열 이름)
2. SUM : 행의 합계를 나타냄
3. AVG : 행의 평균을 나타냄
4. MAX : 행의 최댓값을 나타냄
5. MIN : 행의 최솟값을 나타냄
6. STDENV : 행의 표준편차를 나타냄
7. VARIANCE : 행의 분산을 나타냄
1. STUD_SCORE 테이블을 사용하여 NULL 값을 제외한 음악 점수 보유자를 세려면?
SELECT COUNT(MUSIC_SCORE) AS MUSIC_CNT
FROM STUD_SCORE;
2. STUD_SCORE 테이블을 사용하여 NULL값 및 중복된 값을 제외한 영어 점수 보유자를 세려면?
SELECT COUNT(DISTINCT ENG_SCORE) AS ENG_CNT
FROM STUD_SCORE;
COUNT 함수는 데이터의 검증용으로도 많이 사용됨
=> 특정한 테이블을 만들었을 때 그 테이블에 NULL값이나 중복된 값이 있는지 눈으로 찾기 힘듬
(COUNT로 쉽게 검증 가능)
3. STUD_SCORE 테이블을 사용하여 음악 점수의 평균을 구하려면?
AVG 함수를 사용하면 NULL값을 가진 열은 계산에서 생략되어 전체 평균값이 잘못될 수 있으므로 주의해야함!!
=> COALESCE 사용
SELECT AVG(COALESCE(MUSIC_SCORE, 0)) AS MUSIC_AVG
FROM STUD_SCORE;
4. STUD_SCORE 테이블을 사용하여 수학 점수의 최댓값 및 최솟값을 구하려면?
SELECT MAX(MATH_SCORE) AS MAX_SCORE, MIN(MATH_SCORE) AS MIN_SCORE
FROM STUD_SCORE;
1. 집계 함수를 사용하면 NULL값은 계산에서 무시된다
2. 별칭을 지정할 때 테이블에 존재하는 열 이름이 아닌 새로운 이름으로 지정하는 것이 좋음
3. 숫자형 데이터를 분석할 때 SUM, AVG,MIN,MAX 값을 사용하여 데이터를 검증하는 것은 중요함
조건문 이해하기
CASE WHEN 문장
1. CASE WHEN 문장
[조건1]을 만족하면 [결과값1]을 나타내고, [조건2]를 만족하면 [결과값2]를 나타낸다
나머지는 [결과값3]으로 보여주고 이들 결과값은 [새로운 열 이름]으로 나타내라는 뜻이다!
=> 조건물을 나태낼 때 사용되고 활용도가 높음
SELECT 열 이름1,
CASE WHEN [조건1] THEN [결과값1]
WHEN [조건2] THEN [결과값2]
ELSE [결과값3] END AS 새로운 열 이름
FROM 테이블명;
1. CLERK는 7%, OFFICER는 5%, MANAGER는 3%로 연봉을 인상하기로 했을 때 STAFF_SAL 테이블을 사용하여 각 직원별 인상 연봉을 예상하려면?
SELECT ID, JOB, CURRENT_SAL,
CASE WHEN JOB = 'CLERK' THEN CURRENT_SAL * 1.07
WHEN JOB = 'OFFICER' THEN CURRENT_SAL * 1.05
WHEN JOB = 'MANAGER' THEN CURRENT_SAL * 1.03
ELSE CURRENT_SAL END AS NEXT_SAL
FROM STAFF_SAL;
CASE WHEN 함수에서 EQUAL 조건만 있을 경우 DECODE 함수를 사용할 수 있다
(DBMS 특성에 따라 지원이 안되는 경우도 있음)
DECODE 함수 문법 :
DECODE(열 이름, 조건1, 결과값1,
조건2, 결과값2,
조건3, 결과값3, 기본값) 새로운 열 이름)
'🫧 Database > SQL' 카테고리의 다른 글
| 테이블 합치기 (1) | 2024.02.29 |
|---|---|
| 데이터의 그룹화, 필터링 (1) | 2024.02.27 |
| SQL 기본 함수 배우기 (2) | 2024.02.26 |
| 텍스트 마이닝을 활용한 데이터 조건 주기 (1) | 2024.02.26 |
| 논리연산자를 활용한 데이터 조건 주기 (0) | 2024.02.25 |