
이번 포스팅과 다음 포스팅을 통해 공통 시스템에서부터 또는 공통 시스템으로
데이터를 내보내고 수집하기 위한 코드 예제를 이용해 공부를 해보겠슴다..!
파이썬 환경 설정
앞으로 나올 모든 코드 예제는 파이썬과 SQL로 작성되며 오늘날 데이터 엔지니어링 분야에서 흔히 사용되는 오픈 소스 프레임워크를 사용한다
이번 실습에 사용된 라이브러리를 설치하기 전에 설치할 가상 환경을 만드는 것이 좋다
=> 다양한 프로젝트 및 애플리케이션의 파이썬 라이브러리를 관리하는데 유용한 virtualenv 도구를 사용
(이를 통해 파이썬 라이브러리를 전역이 아닌 프로젝트에 맞는 범위 내에서 설치할 수 있음)
$ python -m venv env
를 통해 env라는 가상 환경을 생성하고
window의 경우
(제가 window 환경에서 실습을 진행중..)
call env/scripts/activate
를 통해 가상 환경을 활성

사진처럼 가상 환경이 활성화됨
결론 : Scripts 파일 안에 있는 activate.bat을 실행시켜 가상 환경을 활성화해준다
이렇게 하면 코드 예제에 필요한 라이브러리를 안전하게 설치할 수 있게된다!
=> pip을 사용하여 라이브러리를 설치하는데 pip는 대부분 파이썬 배포와 함께 제공되는 도구이다
(env) pip install configparser
파일에 추가할 구성 정보를 읽는 데 사용되는 configparser 라이브러리를 pip를 사용하여 설치한다
그리고 나중에 만들 파이썬 스크립트와 동일한 디렉터리에 pipeline.conf 파일을 만든다
(일단 파일을 비워둠 => 나중에 코드 예제로 코드 추가할 예정)
클라우드 파일 스토리지 설정
이번 실습에서 파일 저장에 Amazon Simple Storage Service(Amazon S3) 버킷을 사용한다
=> S3 버킷에 대한 적절한 엑세스 제어 설정은 사용 중인 데이터 웨어하우스에 따라 달라짐
(일반적으로 엑세스 관리 정책에는 AWS Identitiy and Access Management(IAM) 역할을 사용하는 것이 가장 좋음)
각 추출 예제에서는 지정된 소스 시스템에서 데이터를 추출하고 출력을 S3 버킷에 저장한다
(다음 포스팅이될 로드 예제는 해당 데이터를 S3버킷에서 대상으로 로드한다)
=> 이것이 데이터 파이프라인의 일반적인 패턴!
로컬 또는 온프레미스 스토리지를 사용하도록 각 예제를 수정할 수도 있지만
특정 클라우드 제공업체 외부의 스토리지에서 데이터 웨어하우스로 데이터를 로드하려면
추가 작업이 필요할 수 있음!
S3 버킷과 상호 작용하기 위해 설치해야 하는 파이썬 라이브러리가 하나 더 있다
pip install boto3
=> 파이썬용 AWS SDK인 Boto3
S3 버킷과 상호 작용하기 위해 Boto3 파이썬 라이브러리를 사용하기 때문에 IAM 사용자를 생성하고 해당 사용자에 대한 엑세스 키를 생성하고 파이썬 스크립트에서 사용할 수 있는 구성 파일에 키를 저장해야함
(스크립트가 S3 버킷의 파일을 읽고 쓸 수 있는 권한을 갖도록 하는 데 모두 필요함)
먼저 IAM 사용자를 생성해보자

IAM -> 사용자를 클릭한뒤 [사용자생성]을 눌러서 'data_pipeline_readwrite'로 이름을 지정한다
프로그램 방식 액세스를 위해 Console에 대한 사용자 엑세스 권한 제공에 있는 [IAM 사용자를 생성하고 싶음] 을 선택!

다음을 눌러 권한 설정에서 직접 정책 연결을 선택한 후 S3FullAccess를 선택해준다
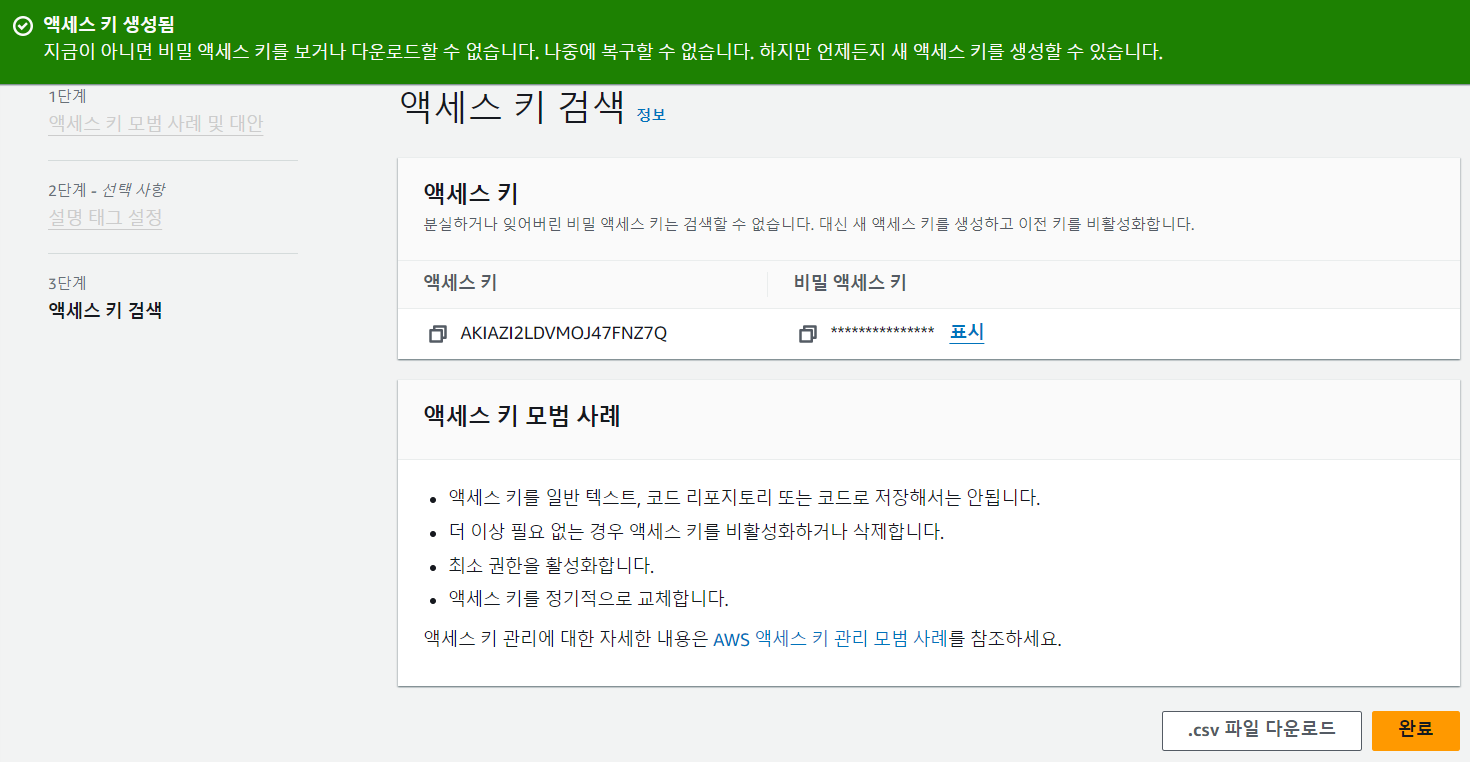
이렇게 생성을 한 후 보안 자격 증명에 들어가서 액세스 키를 생성하고 csv 다운로드를 클릭
=> acces key와 secret key를 알 수 있음

=> bucket_name은 S3 버킷을 생성하고 해당 버킷의 이름을 넣어주고 페이지 오른쪽 상단에 있는 계정 이름을 클릭하여 AWS 계정 ID를 account_id에 입력해줌
MySQL 데이터베이스에서 데이터 추출
MySQL 데이터베이스에서 데이터 추출은
1. SQL을 사용한 전체 또는 증분 추출
2. 이진 로그(binlog) 복제
방법이 있다
SQL을 사용한 전체 또는 증분 추출은 구현하기 훨씬 간단하지만
자주 변경되는 대규모 데이터셋에서는 확장성이 떨어짐
이진 로그 복제는 구현이 더 복잡하지만 원본 테이블의 변경되는 데이터 볼륨이 크거나 MySQL 소스에서 데이터를 더 자주 수집해야 하는 경우에 더 적합함
=> 이진 로그 복제는 스트리밍 데이터 수집을 수행하는 하나의 경로이기도 함

위 사진 처럼 MySQL 데이터베이스의 Orders 테이블을 만들고 행을 몇개 삽입한다
전체 또는 증분 MySQL 테이블 추출
MySQL 테이블에서 전체 또는 일부 열을 데이터 웨어하우스 또는 데이터 레이크로 수집해야 하는 경우 전체 추출 또는 증분 추출을 사용하여 수집할 수 있다
전체 추출에서는 추출 작업을 실행할 때마다 테이블의 모든 레코드가 추출된다
=> 가장 덜 복잡한 접근 방식이지만 대용량 테이블의 경우 실행하는 데 오랜 시간이 걸릴 수 있다
SELECT *
FROM Orders;
증분 추출에서는 추출 작업의 마지막 실행 이후 변경되거나 추가된 원본 테이블의 레코드만 추출된다
마지막 추출의 타임스탬프는
1. 데이터 웨어하우스의 추출 작업 로그 테이블에 저장
2. 웨어하우스의 대상 테이블에서 마지막 업데이트 열의 최대 타임스탬프를 쿼리
하여 검색할 수 있다
SELECT *
FROM Orders
WHERE LastUpdated > {{ last_extraction_run }};
=> last_extraction_run 변수는 추출 작업의 최근 실행 시간을 나타내는 타임스탬프이다!
(일반적으로 데이터 웨어하우스의 대상 테이블에서 쿼리됨)
SELECT MAX(LastUpdated)
FROM warehouse.Orders;
=> 데이터 웨어하우스에서 last_extraction_run에 사용된 결괏값을 확인함
변경할 수 없는 데이터(레코드를 삽입할 수는 있지만 업데이트할 수는 없음)가 포함된 테이블의 경우에는 LastUpdated 열 대신 레코드가 생성된 시간에 대한 타임스탬프를 사용할 수 있다
Orders 테이블이 상당히 큰 경우 다음 추출 작업을 빠르게 수행할 수 있도록 로그 테이블에 마지막으로 업데이트된 레코드의 값을 저장할 수 있음
=> 추출 작업이 시작하거나 완료된 시간이 아니라 대상 테이블의 MAX(LastUpdated) 값을 데이터 웨어하우스에 저장해야 함
증분 추출이 최적의 성능에 이상적이지만 어떤 테이블에 대해서는 가능하지 않을 수 있는 몇가지 단점이 있음
1. 삭제된 행은 캡처되지 않음
=> 원본 MySQL 테이블에서 행이 삭제되면 알 수 없으며 해당 레코드는 대상 테이블에서는 아무것도 변경되지 않은 것처럼 남아있게 된다
2. 원본 테이블에는 마지막으로 업데이트 된 시간에 대한 신뢰할 수 있는 타임스탬프가 있어야 함
=> 소스 시스템 테이블에서 이러한 열이 누락되거나 안정적으로 업데이트되지 않는 경우가 흔함
(개발자가 원본 테이블의 레코드를 업데이트하고 LastUpdated 타임스탬프 업데이트를 잊는 것을 막을 수 X)
그러나 증분 추출을 사용하면 업데이트된 행을 더 쉽게 캡처할 수 있다
로드 단계에서 전체 추출의 경우 일반적으로 목적지에 있는 대상 테이블을 먼저 삭제(truncate)하고 새로 추출된 데이터를 대상 데이터에 로드한다
=> 이 경우 데이터 웨어하우스에 최신 버전의 행이 남음
데이터 로드 단계에서 증분 추출의 경우 결과 데이터가 목적지의 대상 테이블 데이터에 추가된다
=> 이 경우 원본 데이터뿐만 아니라 업데이트된 버전을 모두 가지게 됨
(데이터를 변환하고 분석할 때 두 가지 버전을 모두 가지고 있는 것이 유용할 수 있음)
MySQL 데이터베이스에서 전체 및 증분 추출은 모두 데이터베이스에서 실행되지만 파이썬 스크립트에 의해 트리거되는 SQL 쿼리를 사용하여 구현할 수도 있음!
(env) pip install pymysql
PyMySQL 라이브러리를 설치해주고
MySQL 데이터베이스에 대한 연결 정보를 저장하기 위해 pipeline.conf 파일에 새 내용을 추가해야 한다

전체 추출
이제 extract_mysql_full.py라는 새 파이썬 스크립트를 생성해서
import pymysql
import csv
import boto3
import configparser
parser=configparser.ConfigParser()
parser.read("../pipeline.conf")
hostname = parser.get("mysql_config","hostname")
port = parser.get("mysql_config","port")
username = parser.get("mysql_config","username")
dbname = parser.get("mysql_config","database")
password = parser.get("mysql_config","password")
conn = pymysql.connect(host=hostname, user=username, passwd=password, db=dbname, port = int(port))
if conn is None :
print("Error connecting to the MySQL database")
else :
print("MySQL connection established!")
MySQL 데이터베이스에 대한 연결을 초기화하고
m_query = "SELECT * FROM Orders;"
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query)
results = m_cursor.fetchall()
with open(local_filename, 'w') as fp :
csv_w = csv.writer(fp, delimiter='|')
csv_w.writerows(results)
fp.close()
m_cursor.close()
conn.close()
Orders 테이블의 전체 추출을 실행한다
(추출을 수행하기 위해 pymysql 라이브러리의 cursor 객체를 사용하여 SELECT 쿼리를 실행)
=> 파이프 ('|') 로 구분된 CSV 파일에 씀
python extract_mysql_full.py
위 명령어로 실행을 해보면

CSV 파일이 로컬로 작성되었으므로 나중에 데이터 웨어하우스나 다른 대상에 로드하려면 S3 버킷에 업로드해야함
#aws_boto_credentials 값을 로드
parser = configparser.ConfigParser()
parser.read("../pipeline.conf")
access_key = parser.get("aws_boto_credentials","access_key")
secret_key = parser.get("aws_boto_credentials","secret_key")
bucket_name = parser.get("aws_boto_credentials","bucket_name")
s3 = boto3.client('s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(local_filename, bucket_name, s3_file)
이렇게 코드를 작성하고 실행해보면

버킷에 csv 파일이 성공적으로 업로드 된다!
증분 추출
📌 Redshift에 관한 설정은 뒤에서 나올 데이터 적재 부분에서 다룰 예정이라 코드만 살펴보자!
변경된 사항만을 저장하므로 Last Updated로 부터의 변경사항을 포착하여 데이터 웨어하우스에 적재한다.
스크립트의 시작점으로 extract_mysql_full.py 파일을 복사하여 extract_mysql_incremental.py 사본에서 시작하면 좋다
먼저 원본 Orders 테이블에서 추출한 마지막 레코드의 타임스탬프를 찾는다
=> 이렇게 하려면 데이터 웨어하우스의 Orders 테이블에서 MAX(LastUpdated) 값을 쿼리한다
(env) pip install psycopg2
우선 Redshift 클러스터와 상호작용하기 위해 psycopg2 라이브러리를 설치해주고
Redshift 클러스터에 연결하고 쿼리하여 Orders 테이블에서 MAX(LastUpdated) 값을 가져오는 코드를 작성해봤다
# Redshift db connection 정보를 가져옴
parser = configparser.ConfigParser()
parser.read("../pipeline.conf")
dbname = parser.get("aws_creds", "database")
user = parser.get("aws_creds", "username")
password = parser.get("aws_creds", "password")
host = parser.get("aws_creds", "host")
port = parser.get("aws_creds", "port")
# Redshift 연결
rs_conn = psycopg2.connect("dbname=" + dbname + " user=" + user + " password=" + password + " host=" + host + " port=" + port)
rs_sql = """SELECT COALESCE(MAX(LastUpdated), '1900-01-01') FROM Orders;"""
rs_cursor = rs_conn.cursor()
rs_cursor.execute(rs_sql)
result = rs_cursor.fetchone()
# 오직 하나의 레코드만 반환됨
last_updated_warehouse = result[0]
rs_cursor.close()
rs_conn.commit()
위의 rs_sql의 쿼리문은 데이터 웨어하우스에 데이터가 마지막으로 적재된 시점을 가져오고 그 시점 이후로의 데이터들을 원본 데이터베이스(여기서는 MySQL) 에서 불러와 변경 사항들이 있다면 가져온다.
=> 이전에 MySQL을 연결하며 작성했던 코드와 거의 비슷한데 실행할 sql 쿼리를 살펴보면 LastUpdated 의 MAX 값을 SELECT 하고 있고 만약 값이 없으면 1900-01-01 을 반환해준다!
이 경우 쿼리는 데이터를 변경하지 않으므로 커밋은 필요하지 않지만, 연결을 닫으면서 호출하는 것이 일반적이라 rs_conn.commit() 도 사용했다
last_updated_warehouse에 저장된 값을 사용하여 MySQL 데이터베이스에서 실행되는 추출 쿼리를 수정하기 때문에 이전 추출 작업 실행 이후 Orders 테이블에서 업데이트된 레코드만 가져올 수 있다!
MySQL에서의 추출 쿼리는 다음과 같이 수정했다
m_query = """SELECT * FROM Orders WHERE LastUpdated > %s;"""
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query, (last_updated_warehouse,))
새 쿼리에는 last_update_warehouse 값에 대해 %s로 표시되는 자리 표시자가 포함되어 있는데 이렇게 하면 값이 튜플(데이터 집합을 저장하는 데 사용되는 데이터 유형)로 cursor의 .execute() 함수에 전달된다!
=> 이는 SQL injection(주입) 을 방지하기 위해 SQL 쿼리에 매개변수를 추가해주는 적절하고 안전한 방법이다.
PostgreSQL 데이터베이스에서의 데이터 추출은 MySQL과 매우 유사해서 실습만 진행하고 넘어갔습니다!
MySQL 데이터의 이진 로그 복제는 이해가 잘 안돼서 성장하고 돌아와서 다시 다뤄보도록 하겠습니다...
'🐳 Data Engineering > Data Pipeline' 카테고리의 다른 글
| 데이터 수집 : 데이터 로드 (1) | 2024.07.03 |
|---|---|
| 데이터 수집 : 데이터 추출 (MongoDB, REST API, 카프카 및 Debezium) (1) | 2024.07.02 |
| 일반적인 데이터 파이프라인 패턴 (1) | 2024.05.15 |
| 최신 데이터 인프라 (0) | 2024.05.12 |
| 데이터 파이프라인 소개 (0) | 2024.05.06 |