
국민대학교에서 "오라클로 배우는 데이터베이스 개론과 실습(2판)" 을 이용한
신인수 교수님의 강의 교안을 이용하여 수업 내용을 정리하였습니다
1. 내장함수
SQL 내장 함수
SQL에서는 함수의 개념을 사용하는데 수학의 함수와 마찬가지로 특정 값이나 열의 값을 입력 받아 그 값을 계산하여 결과 값을 돌려준다
=> SQL의 함수는 DBMS가 제공하는 내장 함수(bulit-in function)와 사용자가 필요에 따라 직접 만드는 사용자 정의 함수 (user-defined function)로 나뉨
SQL 내장 함수는 상수나 속성 이름을 입력 값으로 받아 단일 값을 결과로 반환한다
=> 모든 내장 함수는 최초에 선언될 때 유효한 입력 값을 받아야 함
숫자 함수
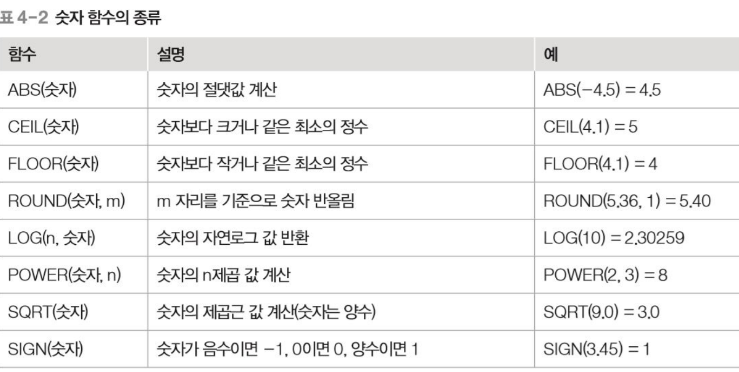

문자 함수
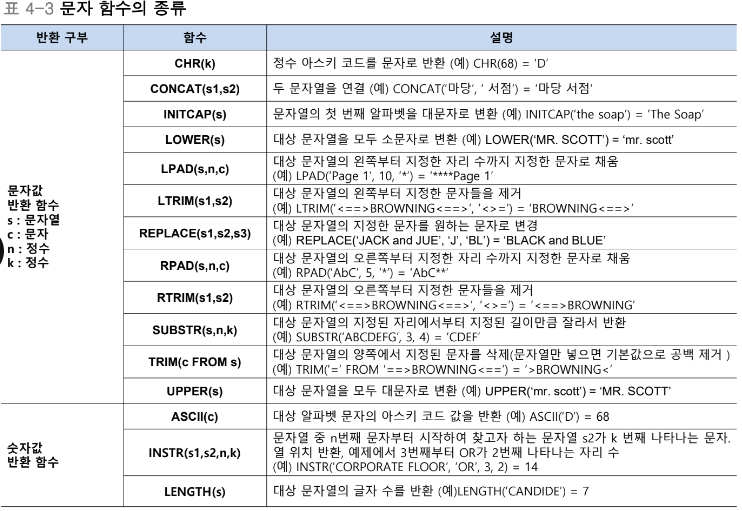
날짜 · 시간 함수

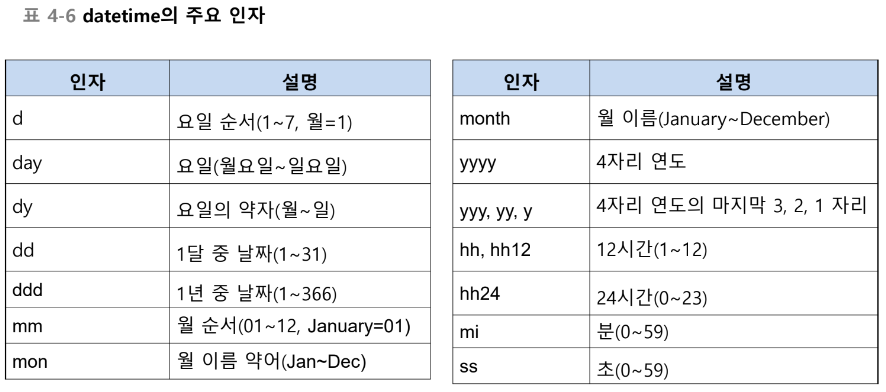

NULL 값 처리
NULL 값이란?
아직 지정되지 않은 값(unknown or not exist)
=> NULL 값은 '0', ""(빈 문자), ' '(공백) 등과 다른 특별한 값이다!
NULL값은 비교 연산자로 비교가 불가능하며 NULL 값의 산술 연산을 수행하면 결과 역시 NULL 값으로 반환된다

집계 함수를 사용할 때 주의할 점
'NULL + 숫자' 연산의 결과는 NULL
=> 집계 함수 계산 시 NULL이 포함된 행은 집계에서 빠짐!
해당되는 행이하나도 없을 경우 SUM, AVG 함수의 결과는 NULL이 되며, COUNT 함수의 결과는 0

NULL 값을 확인하는 방법 - IS NULL, IS NOT NULL
NULL 값을 찾을 때는 '=' 연산자가 아닌 'IS NULL'을 사용한다!
반대로 NULL이 아닌 값을 찾을 때는 'IS NOT NULL' 을 사용

NVL : NULL 값을 다른 값으로 대치하여 연산하거나 다른 값으로 출력한다
NVL(속성, 값) : 속성 값이 NULL 이면 '값' 부분으로 대치한다!

ROWNUM
내장 함수는 아니지만 자주 사용되는 문법이다!
오라클에서 내부적으로 생성되는 가상 컬럼으로 SQL 조회 결과의 순번을 나타낸다
=> 자료를 일부분만 확인하여 처리할 때 유용함

2. 부속질의
부속질의(subquery)란?
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의를 말한다
=> 다른 테이블에서 가져온 데이터로 현재 테이블에 있는 정보를 찾거나 가공할 때 사용한다
보통 데이터가 대량일 때 데이터를 모두 합쳐서 연산하는 조인보다 필요한 데이터만 찾아서 공급해주는 부속질의가 성능이 더 좋음!
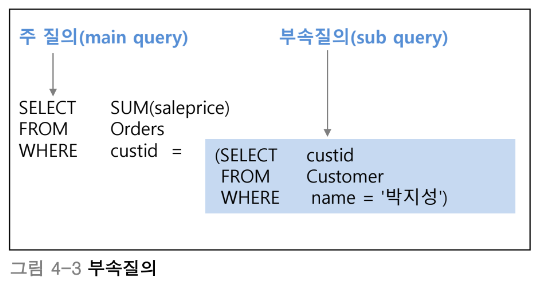
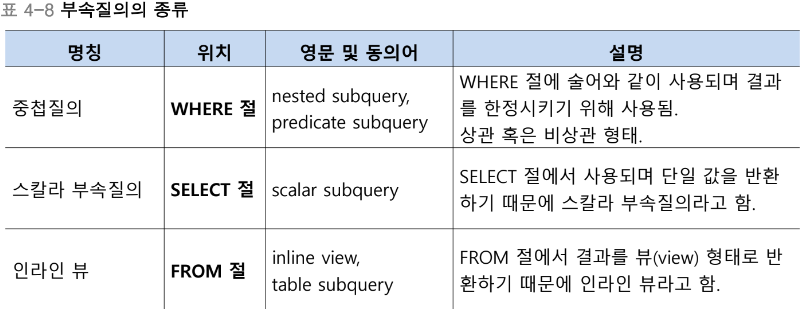
중첩 질의 - WHERE 부속질의
비교 연산자
부족질의가 반드시 단일 행, 단일 열을 반환해야 하며, 아닐 경우 질의를 처리할 수 없음
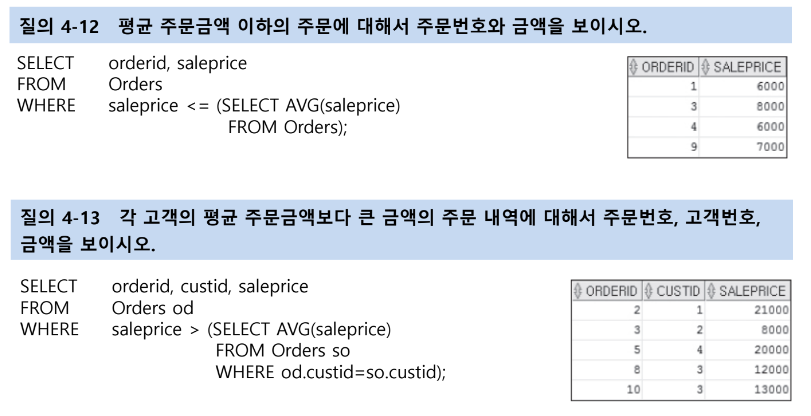
IN, NOT IN
IN : 주질의 속성 값이 부속질의에서 제공한 결과 집합에 있는지 확인하는 역할을 함
=> 부속질의 결과 다중 행을 가질 수 있고 주질의는 WHERE 절에 사용되는 속성 값을 부속질의의 결과 집합과 비교해 하나라도 있으면 참이된다
NOT IN : IN과 반대로 값이 존재하지 않으면 참이 됨

ALL, SOME(ANY)
ALL은 모두, SOME(ANY)은 어떠한(최소한 하나라도)이라는 의미를 가짐

EXISTS, NOT EXISTS
데이터의 존재 유무를 확인하는 연산자이다
주질의에서 부속질의로 제공된 속성의 값을 가지고 부속질의에 조건을 만족하여 값이 존재하면 참이되고, 주질의는 해당 행의 데이터를 출력한다
NOT EXISTS의 경우 이와 반대로 동작함
구문 구조 : WHERE [NOT] EXISTS (부속질의)

스칼라 부속질의 - SELECT 부속질의
스칼라 부속질의(scalar subquery)란?
SELECT절에서 사용되는 부속질의로, 부속질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환한다
스칼라 부속질의는 원칙적으로 스칼라 값이 들어갈 수 있는 모든 곳에 사용 가능하며, 일반적으로 SELECT문과 UPDATE SET 절에 사용된다
=> 주질의와 부속질의와의 관계는 상관/비상관 모두가능함

예를들어 마당서점의 고객별 판매액을 보이는 SQL문을 살펴보면
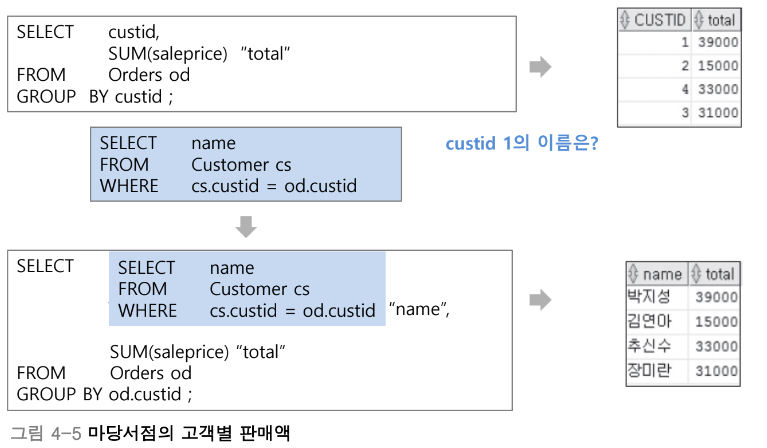
이렇게 된다!
UPDATE SET 예제를 살펴보면
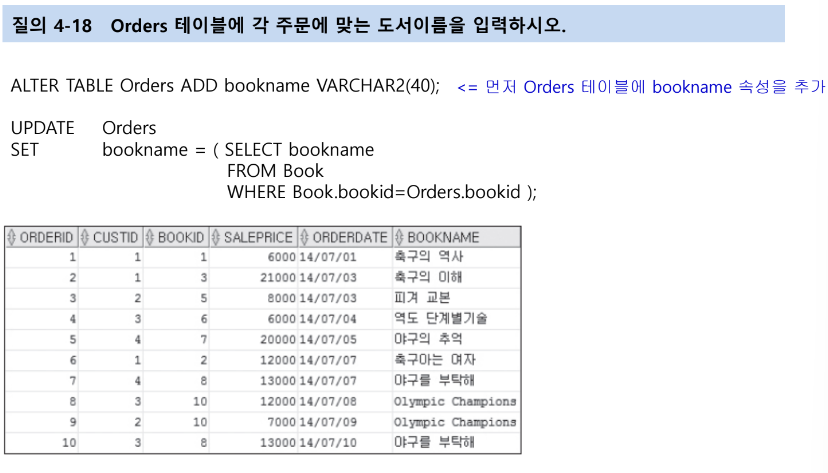
인라인 뷰 - FROM 부속질의
인라인 뷰(inline view)란?
FROM절에서 사용되는 부속질의로 테이블 이름 대신 인라인 뷰 부속질의를 사용하면 보통의 테이블과 같은 형태로 사용할 수 있다
=> 부속질의 결과 반환되는 데이터는 다중 행, 다중 열이어도 상관 없음
(다만 가상의 테이블인 뷰 형태로 제공되어 상관 부속질의로 사용될 수는 없음)


3. 뷰
뷰(view)는 하나 이상의 테이블을 합하여 만든 가상의 테이블
장점
- 편리성( 및 재사용성) : 자주 사용되는 복잡한 질의를 뷰로 미리 정의해 놓을 수 있음
=> 복잡한 질의를 간단히 작성, 미리 정의된 뷰를 일반 테이블처럼 사용하여 편리함 - 보안성 : 각 사용자별로 필요한 데이터만 선별하여 보여줄 수 있음 (중요한 질의의 경우 질의 내용을 암호화 가능)
=> 개인정보(주민번호)나 급여, 건강 같은 민감한 정보를 제외한 테이블을 만들어 사용 - 논리적 데이터 독립성 제공
=> 개념 스키마의 데이터베이스 구조가 변하여도 외부 스키마에 영향을 주지 않도록하는 논리적 데이터 독립성 제공
뷰의 특징
1. 원본 데이터 값에 따라 같이 변함
2. 독립적인 인덱스 생성이 어려움
3. 삽입, 삭제, 갱신 연산에 많은 제약이 따
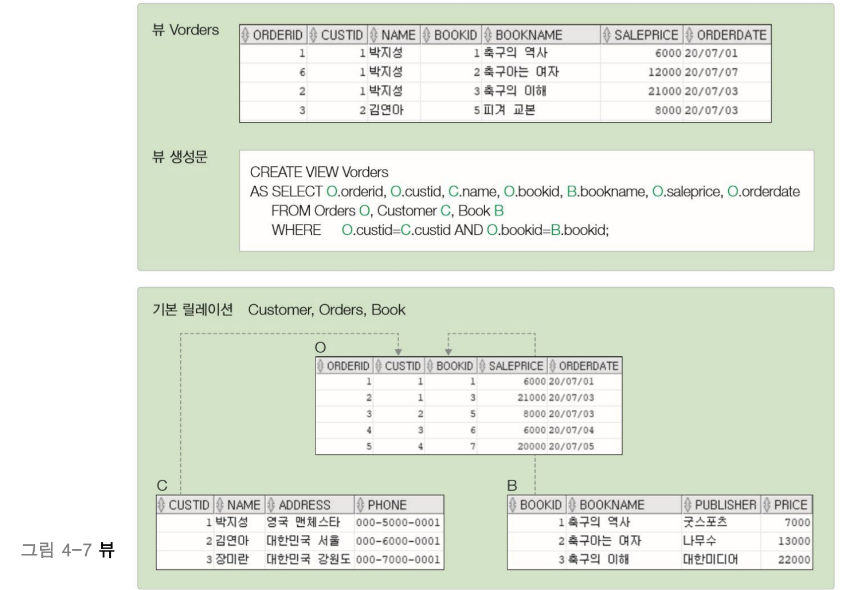
뷰의 생성
기본 문법은
CREATE VIEW 뷰이름 [(열이름 [,...ㅜ])]
AS SELECT 문
(뷰의 SELECT 문은 Data Dictionary에 저장되며, 뷰의 조회 시 읽어와서 실행됨)


뷰의 수정
기본 문법은
CREATE OR REPLACE VIEW 뷰이름 [(열이름 [,...n])]
AS SELECT 문
이다!

뷰의 삭제
기본문법은
DROP VIEW 뷰이름 [,...n];
이다!

4. 인덱스
데이터베이스의 물리적 저장

데이터가 저장되는 곳 : 하드디스크, SSD, USB 메모리 등
하드디스크 : 원형의 플레이트(plate)로 구성되어 있고, 이 플레이트는 논리적으로 트랙으로 나뉘며 트랙은 다시 몇 개의 섹터로 나뉨
=> 원형의 플레이트는 초당 빠른 속도로 회전하고, 회전하는 플레이트를 하드디스크의 액세스 암과 헤더가 접근하여 원하는 섹터에서 데이터를 가져옴
- 하드디스크에 저장된 데이터를 읽어 오는 데 걸리는 시간은 모터에 의해서 분당 회전하는 속도(RPM)
- 데이터를 읽을 때 엑세스 암이 이동하는 시간(latency time)
- 주기억장치로 읽어오는 시간(transfer time)에 영향을 받음

인덱스의 필요성 (in memory)
* 오라클 저장영역
Tablespace > Segment > Extents > Block
질의 검색 시 data block(여러 개의 record를 저장하는 저장단위, 2KB, 4KB, ...)을 읽는 횟수의 최소화가 필요함
Disk에 있는 데이터는 memory에 있는 데이터에 비하여 읽어들이는 속도가 10000배 정도 소요됨
인덱스와 B-tree
인덱스(index, 색인)
도서의 색인이나 사전과 같이 데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조이다

인덱스의 특징
- 인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성함
- 빠른 검색과 함께 효율적인 레코드 접근이 가능함
- 순서대로 정렬된 속성과 데이터의 위치만 보유하므로 테이블보다 작은 공간을 차지함
- 저장된 값들은 테이블의 부분집합이 됨
- 일반적으로 B-tree 형태의 구조를 가짐
- 데이터의 수정, 삭제 등의 변경이 발생하면 인덱스의 재구성이 필요함
오라클 인덱스
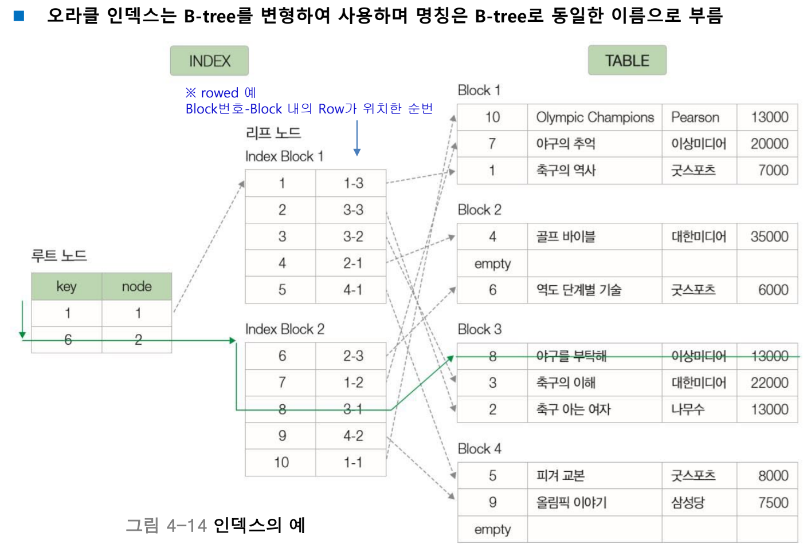
오라클 인덱스의 종류

인덱스의 생성
인덱스 생성 시 고려사항
- 인덱스는 WHERE 절에 자주 사용되는 속성이어야 함
- 인덱스는 조인에 자주 사용되는 속성이어야 함
- 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음(테이블 당 4~5개 정도 권장)
- 속성이 가공되는 경우 사용하지 않음
- 속성의 선택도가 낮을 때 유리함(속성의 모든 값이 다른 경우)
- 선택도 (selectivity) = 1 / (서로 다른 값의 개수)

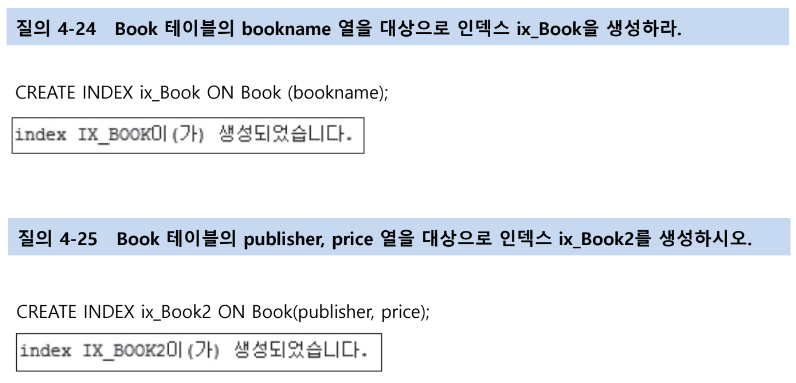
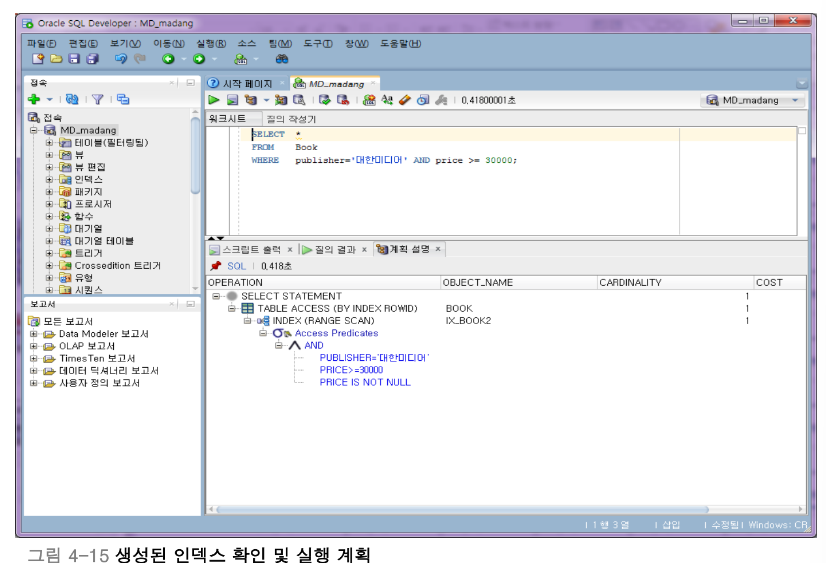
인덱스의 재구성과 삭제
인덱스의 재구성은 ALTER INDEX 명령을 사용함
단편화(fragmentation) 제거를 위해 사용 => REBUILD

'Database > 데이터베이스' 카테고리의 다른 글
| Chapter 06. 데이터 모델링 (0) | 2024.05.15 |
|---|---|
| Chapter 05. 데이터베이스 프로그래밍 (1) | 2024.04.16 |
| Chapter 03. SQL 기초 (1) | 2024.04.14 |
| Chapter 02. 관계 데이터 모델 (1) | 2024.04.12 |
| Chapter 01. 데이터베이스 시스템 (2) | 2024.04.10 |