
국민대학교에서 "클라우드 컴퓨팅" 교과목을 진행하시는
이경용 교수님의 강의 교안을 이용하여 수업 내용을 정리하였습니다
Decoupling Modules

Decoupling Modules란 전체 시스템을 독립적인 컴포넌트로 디자인 하는 것임
=> 각 컴포넌트 간의 종속성을 최소화함으로 특정 컴포넌트에서 발생한 문제가 다른 곳으로 전파되는 것을 방지해야함
- Tightly coupled : 한 응용 서버의 문제가 모든 웹서버에 문제를 미칠 수도 있음
- Loosely coupled : 로드밸런서가 응용 서버의 실패를 가려줌
(로드 밸런서는 health check를 실행함)
시스템이 loosely coupled 될 수록 시스템의 확장성을 보장하는 것이 쉬워짐
모듈을 decoupling 하는 방법
서버를 만들지 말고 서비스를 만들면됨
=> 클라우드에서 제공되는 다양한 서비스 활용 가능
서버를 구축하여 모든 서비스를 만드는 시도는 좋지 않음
=> 어플리케이션이 아니라 DB같은건 EC2에 올리지 않고 RDS를 이용하면됨
(고가용성과 관리비를 포함한 인건비를 생각하면 RDS가 유리할 수 있음)
Decoupling 하지 않는 시스템 디자인
- 응용은 지속적으로 동작하는 서버에서 동작
- 응용은 다른 응용과 직접적으로 통신
- 정적 파일들은 서버 인스턴스의 파일 저장소에 존재
(stateful) - 백엔드 서버가 다양한 일을 처리
(사용자 인증, 사용자 파일 저장 등)
=> MSA가 아니라는 뜻
위와 같은 예제는 다양한 클라우드 서비스를 활용하여 서비스로 분리 가능함
Service-Oriented-Architecture (SOA)
여러 응용 컴포넌트들은 다른 컴포넌트들에게 약속된 기법으로 서비스를 제공하는 구조임
- 서비스는 완전하게 동작하는 독립적인 개체
- 운영체제, 프로그래밍 언어 등의 제약을 다른 서비스에게 내포하지 않아야 함
- 추상화를 통한 API를 제공해줌
(서비스 세부 사항을 외부에 알릴 필요 X)

SOA의 목적은 응용 서비스들간의 coupling을 최소화 하는 데 있음
SOA에서 작고 독립적인 프로세스를 마이크로 서비스라고함
=> 이 마이크로 서비스 프로세스는 하나의 작은 작업을 하는 것에만 집중
마이크로서비스가 여러개 합쳐져서 하나의 완벽한 응용 서비스를 제공해줄 수 있음
=> 서비스들은 손쉽게 교체 및 업그레이드 가능
(기존의 SOA에서 서비스는 큰 하나의 서비스를 정의)
시스템 구조 스타일 비교

마이크로 서비스별로 테스트할 시나리오가 감소됨
=> 테스트 시나리오의 감소로 업데이트에 대한 비용이 최소화됨
(하나의 큰 monolithic 서비스의 경우 업데이트 범위 파악이 어려워 테스트가 어려움)
결론적으로는 각각의 서비스가 독립적으로 확장될 수 있도록 설계
마이크로 서비스를 활용한 Loose Coupling
1. 개별 컴포넌트는 손쉽게 테스트 되어야 하고 업그레이드가 쉬워야함
=> 다른 서비스에 제공해주는 인터페이스 변경 최소화
(시스템의 업데이트가 인터페이스의 변경에 미치는 영향을 최소화)
2. 간단한 API(인터페이스)의 사용
=> 서비스를 사용하는데 소요되는 비용 절감
(많은 것을 외부에 노출하지 않으므로 업데이트가 쉬워짐)
3. 기술의 변화 속도는 빠르고, 각 응용이 필요로 하는 요구 사항이 다르기에 특정 기술에 얽매이지 X
4. 서버를 stateless로 디자인
=> 서버는 언제든지 바꿀 수 있는 자원으로 인식되어야 함
(특정 시점의 서버 상태가 시스템의 안정된 운용에 영향을 미쳐서는 안됨)
예를 들어 사용자가 온라인 쇼핑몰에서 카트에 아이템을 담았는데 아이템이 서버에 저장되는 상황에서 서버가 종료되면 카트의 아이템은 사라지는 경우를 생각해볼 수 있음
=> 외부의 fully-managed 자료 저장소 서비스를 활용하면됨
또한, stateless의 경우 Auto Scaling을 활용한 자원의 추가/제거 가 쉽기에 확장성이 용이함
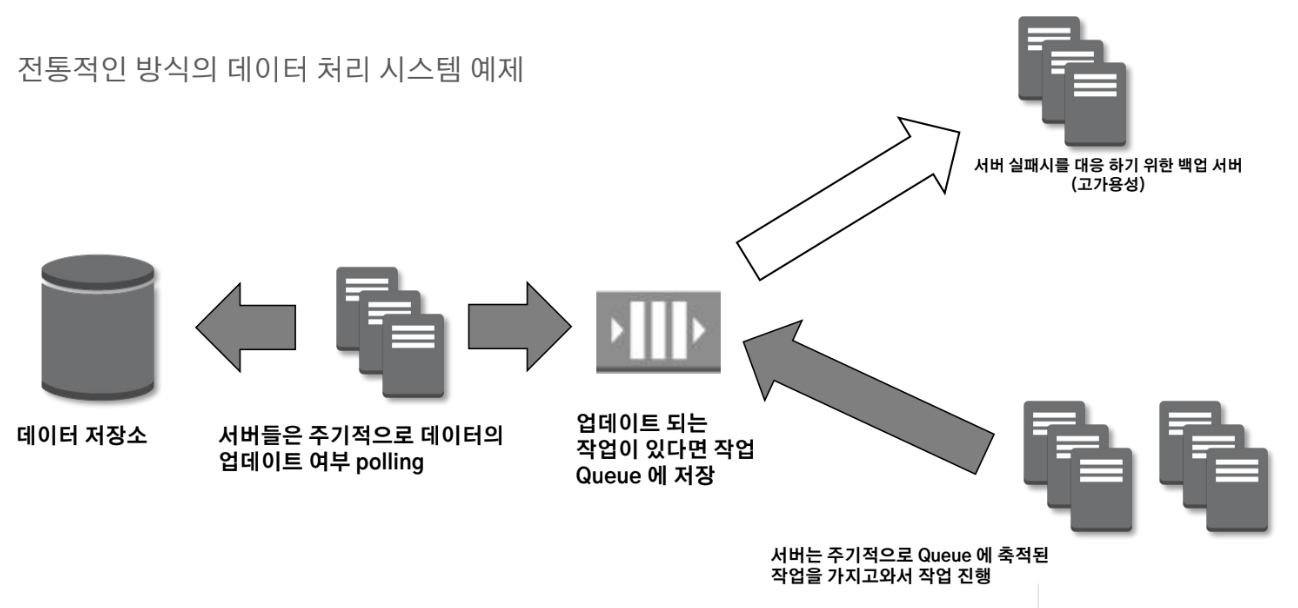
메시지 큐를 활용한 서비스 decoupling
AWS에서 제공하는 Simple Queue Service (SQS)는 fully-managed 메시지 큐잉 서비스임
=> 메시지의 유실이나 서비스의 가용성에 대한 염려 X

Queue를 활용함으로 다른 컴포넌트들이 비동기 방식으로 메시지를 주고 받게 해줌
Amazon SQS의 특징
Scalable
=> Fully-managed 서비스로 확장성을 제공해주며 수백만건의 메시지 처리 가능
(읽기/쓰기 작업의 병렬 작업 지원)
Reliable
=> 모든 메시지들은 여러 데이터 센터의 여러 서버에 복제되어 있음
(메시지 접근을 위한 API credential을 지원)
분산 큐에서 메시지 읽어오기
큐잉 서비스에 6개의 서버가 존재하는 예제를 살펴보면

메시지 read 요청시 임의의 서버 선택 후 읽기가 실행됨
이 때 회색 서버를 선택시, 메시지 E가 전달이 되지 않아 추가적인 read시에 E가 전달됨
분산 Queue를 통한 메시지 전달시 주의점
Message ordering
- SQS 서비스는 메시지가 write된 차례를 보존하려고 하지만 분산 저장소의 특성상 이는 보존 X
- Ordering의 보존이 필요할 경우 메시지 자체에 sequence 정보 삽입 필요
At least once delivery
- SQS에서 메시지들은 여러 분산 서버에 저장되어 있기에, 같은 메시지가 여러번 수신 될 수 있음
(고가용성을 위함) - 응용 프로그램이 idempotent 하게 만드는 것이 중요함
(특정 시스템이 값을 여러번 받아서 처리하더라도 결과가 동일하게)
Message sampling
- 메시지를 가지고 오는 서비스를 랜덤하게 선택하기에, 반복적인 polling을 실시해야함
메시지의 중복 처리 방지법
Amazon SQS visibility timeout
- 여러 컴포넌트들이 하나의 메시지를 중복해서 처리하는 것을 방지해줌
- 프로세스가 메시지를 읽어가면 해당 메시지는 lock됨
- 특정 시간 이후 해당 메시지가 삭제되지 않으면, lock은 해제되고 다른 프로세스가 처리 가능해짐
Amazon SQS 타입
Standard queue (분산 큐)
- 최소 한번의 배달은 보장함
- 메시지가 큐에 삽입된 순서는 보장 X
FIFO queue
- 메시지의 전달 차례가 지켜지는 것을 보장 함 (First-In-First-out)
- 메시지는 한번만 처리되는 것이 보장 됨 (반복 처리 X)
- 최대 처리 throughput이 제한됨
(초당 300건의 메시지 송,수신) - 메시지의 발신 차례를 보존 하는 것은 보내는 쪽인 응용이 담당해야함
(싱글쓰레드 기반으로 메시지 전송하면 순서가 자동으로 보존됨 멀티쓰레드는 쓰레드간 동기화를 관리해야함)
메시지 공지 (Notification) 서비스
Amazon Simple Notification Service (SNS)는 여러 응용 서비스 간에 notification을 주고 받을 수 있게 해주는 서비스임
- 특정 토픽에 메시지가 등록되면, 해당 메시지는 구독하는 응용들에게 전달됨
- 메시지를 등록시에 어떤 응용에게 전달되는지 특정 할 필요가 없음
(pub-sub model) - Fully-managed 서비스로 메시지의 수신, 발신 용량의 제한이 없음
(과금은 됨..) - 하나의 발신 메시지가 여러 수신 개체들에게 전달 될 수 있음
Amazon SNS 특징들
메시지를 보내는 역할을 담당하며, 수신/처리를 보장하지 않음
메시지의 송신/수신 차례는 보장되지 않음
=> 네트워크 이슈 등으로 인해서 out-of-order 발생 가능 하며, 이를 체크하지 X
SNS의 Subscribers로는 Email, HTTP, SMS, Amazon SQS, AWS Lambda 가 있음
Amazon SNS vs Amazon SQS

1. SQS는 message persistence가 보장됨
(메시지가 반드시 처리 될 수 있음을 보장)
2. SNS는 여러 응용에게 메시지를 동시에 보내지만, SQS는 하나의 응용이 메시지를 처리함
3. SNS는 지속적인 polling 없이 메시지를 전달 받게 해줌
4. SQS는 sender/receiver가 동시에 abailable하지 않아도 무방함
SNS와 SQS를 활용한 예제


Dynamo DB를 활용한 컴포넌트 Decoupling
DynamoDB는 NoSQL DB로 join하는 등의 복잡한 쿼리 기능은 제공하지 않음
(get, set등을 사용)
- key-value 저장 서비스 제공 (fully-managed)
- 각 컴포넌트의 결과물을 저장함과 (write) 동시에 다른 컴포넌트들이 해당 결과물을 읽게 함(read)
=> 이를 이용해 컴포넌트간 decoupling 기능을 제공 - Fault-tolerance 기능 내재
Amazon SQS와 DynamoDB를 활용하는 응용 패턴

- 온라인 앱에서 사용자 투표 결과가 발생하며 이는 SQS에 저장
- ASG의 EC2 인스턴스가 투표 결과의 유효성 검증 후 결과를 DynamoDB 테이블에 저장함
- 유효한 투표 결과를 보여주는 인스턴스 존재
웹 페이지 구성

웹 기반 응용의 특성
웹 서비스가 가용하지 않을 경우 매출 감소나 브랜드 이미지 및 고객을 잃게 될 수 있음
또한, 보통 TV같은 하드웨어 기반 서비스가 고장나면 고쳐서 사용하려고 (즉시 새로 사지 X) 하지만 구글 사이트 검색 불가시 다른 벤더를 활용하여 즉시 대체가 가능하기에 더 예민함
웹 자료 저장 패턴
웹의 자료들중 변하지 않는 내용의 정적 자료가 있음
(웹페이지에 기록된 텍스트 - HTML, 이미지, 비디오 자료 등)
이런 정적 자료를 웹 응용 서버 (EC2) 에서 제공시 문제점들이 있는데
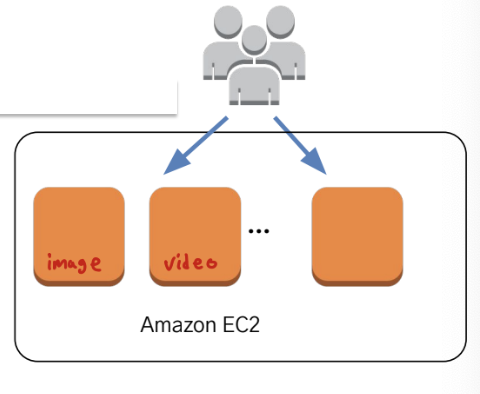
- EC2 서버의 위치에 따라 가변적인 사용자의 위치 마다 응답시간이 길어질 수 있다는 점
(사용자가 전세계 어디서든 접근할 수 있으므로) - 사용자가 업로드한 자료가 있을 경우 해당 자료는 모든 웹서버에서 접근이 가능해야함
- stateful 해짐
보다 나은 정적 파일의 저장 방법

HTML, CSS, Image, Videoe 등의 정적 파일은 Amazon S3에 저장 후 해당 위치로 부터 제공해줌
(S3는 object 저장소)
S3는 HTTP URL을 통해서 공개적으로 접근이 가능한
(public 설정이 필요)
S3 오브젝트는 각 버킷 별로 key-value 타입으로 저장됨
=> 각 버킷별 Map (or dictionary) 생성하여 key는 object 이름, value는 실제 오브젝트로함
CloudFront를 활용한 빠른 응답 시간 제공
Amazon CloudFront란 AWS에서 제공하는 Content Delivery Network (CDN) 서비스임
=> 많이 접근하는 것을 가까운 곳에 cache 해두는 것

- 전세계에 걸쳐 있는 Edge location에서 캐쉬 서비스 제공
- 분산 저장 및 캐싱을 통한 빠른 응답 시간 제공
- 실제 데이터 저장소 부하 감소
- CloudFront에 저장된 파일에 대한 요청이 올 경우 요청 사용자와 지리적으로 가까운 CloudFront Edge location으로 자동으로 요청이 전달됨
=> 요청 파일이 캐싱시 즉각 제공하고 만약 요청 파일이 없을 경우 실제 데이터 소스 (S3)에서 파일을 읽어 들인 후 제공
CloudFront에서 정적/동적 데이터 제공 및 웹 호스팅 예제

동적 자료의 경우 TTL (Time to Live)를 짧게 설정 가능
=> CloudFront가 원 자료 저장소에 파일의 업데이트 여부를 확인함
(변경된 데이터가 캐시에 반영되지 않은 상태로 사용자에게 전달되는 것을 방지하기 위함)

흐름은 Route53 -> CloudFront -> LoadBalancer 또는 S3 (필요 내용에 따라) 이고
DB의 경우 RDS를 활용한 master-slave 구조이고 Elastic cache로 DB의 빠른 접근을 고려하였음
CloudFront를 동작 시키는 방법

1. Origin 서버 설정 (S3, LoadBalancer 등)
2. Origin 서버에 데이터 업로드
3. CloudFront에 origin 서버 등록 및 필요 옵션 설정
4. CloudFront 서비스별로 URL 생성 (http end-point)
5. CloudFront가 각 Edge location에 object에 대한 정보 배포
CloudFront에서 Cache Control Header 활용
HTTP 요청의 Cache Control Header를 활용하여 정적/동적 자료 여부를 설정 할 수 있음
=> Expiration 시간 (TTL) 을 정적인 자료는 길게 동적인 자료는 잛게 설정
TimeToLive(TTL)은 캐쉬된 객체를 expire 시키는 시간으로
TTL이 지났을 경우 CloudFront는 Origin에 If-Modified-Since로 파일의 업데이트 여부 확인
=> 변하지 않았다면 캐쉬된 정보 제공
파일명의 변경은 즉각적인 cache invalidate를 시킴
(파일명의 재사용은 좋지 않음 => 모든 지역에서 synchronous하게 캐쉬 업데이트가 발생하지 않기에)
Amazon API Gateway를 활용한 컴포넌트 Decoupling
Amazon API Gateway는 웹서버의 기능을 해주는 API를 생성하게 해줌
- 백엔드 서비스들 (데이터, 비즈니스 로직, 응용 예제)에 요청을 전달
- 원시적으로 80번 포트를 통한 HTTP 기능 제공
- Fully Managed 서비스
(서비스 내부에 DDos 공격 방어 메커니즘이 내재되어 있음) - 수십만건의 동시 요청 처리 가능
- 다른 AWS 서비스와의 연동성이 좋음
(EC2, Lambda)
Amazon API Gateway 활용 예제

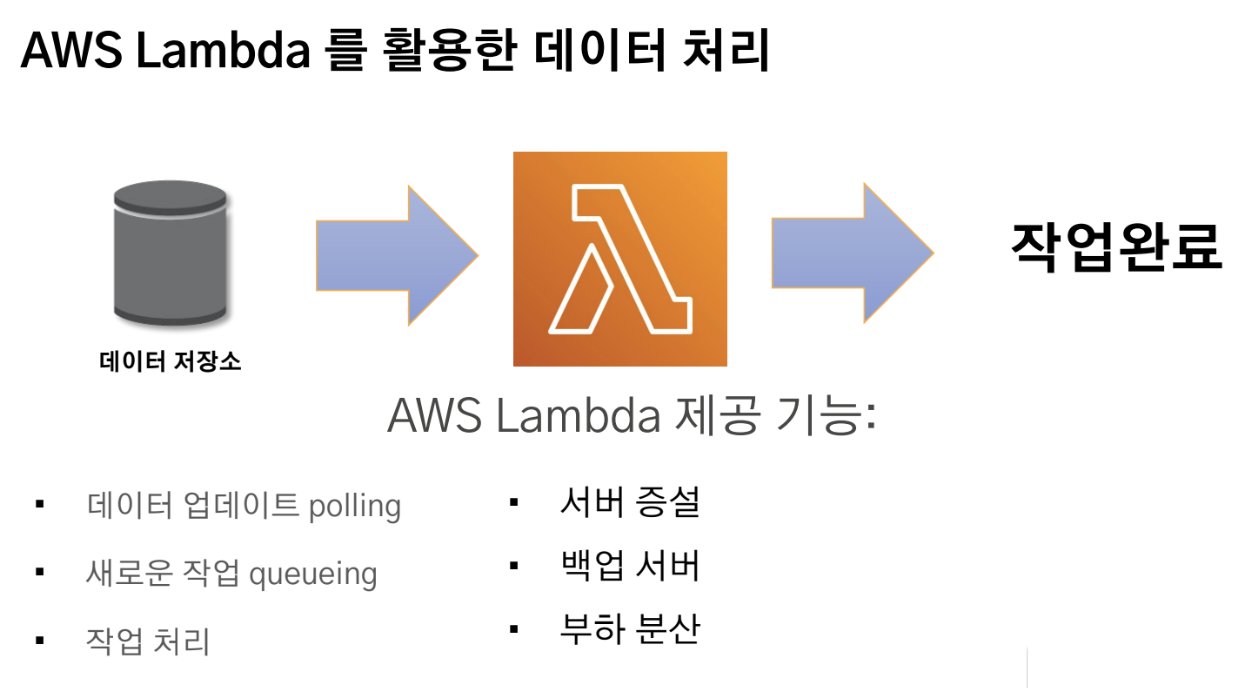
AWS Lambda를 활용한 서비스 decoupling
AWS Lambda는 사용자로 하여금 자원 관리의 부담없이 사용자 작성 코드를 동작하게 해줌
- 인스턴스의 provisioning (시작/종료/업데이트) 관리는 AWS의 책임
- 운영체제의 보안 패치
- 저렴한 가격
의 특징이 있음
AWS Lambda에서는 stateless 응용이 적합함
(Lambda는 호출될 때마다 새로운 컨테이너에서 실행됨)
=> Stateless 응용은 뛰어난 확장성을 가지고 있고 어떤 서버에서 동작해도 결과의 차이가 없기 때문에
기존의 서버를 Lambda로 변경함으로 응용 예제를 stateless로 설계 하게 되며, 이는 컴포넌트 간의 decoupling을 향상 시킴
=> Stateful하게 사용하려면 DB나 CloudFront로 캐싱하는 것들을 따로 배치해야함
AWS Lambda 특징
AWS Lambda가 제공해주는 서비스
- 서버관리
- 필요에 의한 자원 추가 및 제거
(Auto-Sacling) - 코드 배포
- 실행환경 업데이트
(운영체제 및 보안 관련 사항들) - 실행 메트릭 수집 및 메시지 로깅
사용자 관점에서의 특징
- 지원 언어에 제한이 없고, 사용자가 실행 런타임을 커스터마이즈 가능
- 사용자가 작성한 커스텀 코드 및 라이브러리 활용 가능
- 병렬 수행 가능
- 사용하지 않는 자원에 대해서는 과금 X
어떻게 활용할 수 있을까?
1. 서버의 provisioning 없이 사용자가 작성한 코드가 실행되고 실제로 동작한 시간에 비례한 과금이 이뤄짐
(코드 동작하지 않으면 과금되지 않음)
2. 다른 AWS 서비스들이 Lambda 함수를 동작시키게 할 수 있음
=> 반대로 Lambda도 다른 AWS 서비스들을 동작 시킬 수 있음
3. 다른 웹서비스나 앱에서 직접 호출이 가능함
4. EC2 인스턴스가 분리 가능한 간단한 작업을 한다면 람다를 활용할 수 있음
=> 많은 응용들을 실제로 분리 가능하고 EC2 운용시 필요한 고가용성, scalability, deployment 등의 다양한 이슈를 고려할 필요 X
AWS Lambda의 사용 환경 설정
컴퓨팅 자원의 할당의 경우
사용자는 람다 함수 설정 시 최대 메모리 사용량을 지정하고 이 비례한 CPU 성능을 제공함
=> 로컬 디스크의 경우 500MB가 할당 되지만 영속적이지 X
함수 실행 패키지 (코드 및 라이브러리 포함) 사이즈 제한의 경우
디폴트 250MB 정도이고 큰 사이즈의 패키지 사용을 위해서는 Layer 또는 EFS(Elastic File System)을 사용함
=> 함수 실행 컨테이너 이미지로 생성하여 활용 가능함 - 10GB가 최대
(docker Image로 Amazon ECR에 올려서 사용)
코드의 최대 실행 시간은 15분으로 제한되기에 오래 걸리는 작업의 경우 SQS의 도입을 고려해볼 수 있음
Cold-Start
- 함수 실행을 위한 런타임 환경이 준비되어 있다면 빠르게 실행되지만 준비되어 있지 않다면 환경 준비에 오랜 시간이 걸림
- 실제 함수 실행시에는 handler 코드만 실행되며, 나머지 부분의 코드 변수 및 상태는 유지됨
=> Provisioned concurrency를 활용한 cold-start 문제 해결 가능
(추가 과금 필요)
AWS Lambda 실행 방법
1. 람다 코드 작성
- 람다 서비스 코드 에디터 활용
- 코드와 필요한 라이브러리들을 압축하여 (.zip) 람다에 업로드
- 컨테이너 이미지에 실행 코드 등록
2. 서비스를 시작할 이벤트를 등록
- 다른 AWS 서비스
- 주기적인 실행 등
3. 함수 실행에 필요한 메모리 사이즈 설정 (128MB ~ 10GB)
4. 타임아웃 설정
5. 필요하다면 VPC 설정
(다른 AWS 서비스 활용시에)
AWS Lambda의 응용 예제들


Decoupling 예제



'Infra > AWS' 카테고리의 다른 글
| Cloud Deployment Automation (4) | 2024.10.19 |
|---|---|
| Cloud High Availability (1) | 2024.10.17 |
| Cloud Network (3) | 2024.10.16 |
| Cloud Basic Service (13) | 2024.10.14 |
| Distributed System (5) | 2024.10.06 |